

現役エンジニア (メーカー勤務10年 → 某大手電機会社 勤務)
子供の頃RPGツクールに触れて独学でプログラミングを習得
AI研究、ゲーム、キャンプが生きがい
今ワクチンの副反応でフラフラしながら記事書いています・・・。
まだ残暑の中に鳥肌が止まらないけど体温は39度を超えるという恐怖体験中です。
皆さんもワクチン接種の時は病人食や飲み物の準備を怠らないようにしましょう!
それでは株価予測モデルの予測結果の考察について紹介します!
目指せ不労所得!
前回のおさらい
さて、前回の記事では1から実装したディープラーニングということで
オリジナルモデルを作成し株価の上昇/下降の的中率を調査しました。
結果として、 上昇的中率は 約57[%]、下降的中率は 50[%] となりました。
↓ 作成したモデルや検証内容の詳細は前回の記事をご覧ください ↓

今回の内容
今回はディープラーニングで株価予測してみた第2段ですが新しいモデル等はなく
前回の予測結果で興味深いことがあったのでデータ整理と今後の方策についてお話しようと思います。
特に銘柄を増やして株価予測データのプロットを作成したので考察も載せていきます!
興味深いデータが取れたのでぜひ見ていって下さいね!
株価予測データプロット
扱っていた銘柄は「輸送用機械」に限定して無作為に30銘柄選んで株価の予測をしてみました。
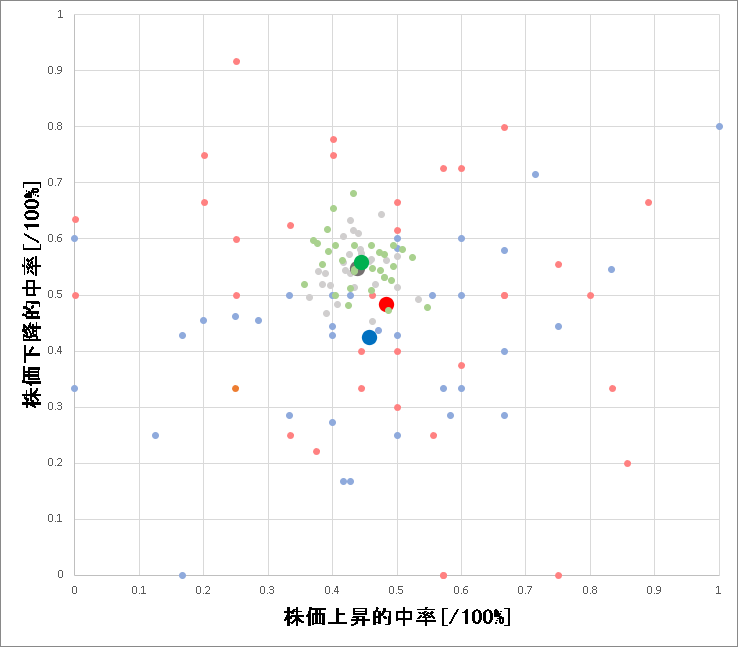
下記が株価上昇的中確立/下降的中確立のプロットとなります
赤色が自銘柄データを入れて学習した場合、青色が他銘柄データのみで学習した場合になります。
大きい点はそれぞれの平均値です。

株価上昇側は的中率が50[%]を割っていますが株価下降側の的中率は50[%]を超えています。
本当は株価上昇側の的中率が高い方がありがたいのですが・・・。残念です。
結果として株価上昇/下降的中率共に結構バラつきがある内容となりました。
また自銘柄データを入れても入れなくても的中率はそれほど変わらないことも分かりました。
株価上昇的中率方向と下降的中率方向でt検定を実施してみましたが
有意差はありませんでした。
とはいえ個人的には自銘柄データをデータセットに入れ込む方が
気持ちが落ち着くので他銘柄のみの学習は今後しないと思います。
改めてデータ整理
ただ先ほどのデータをよくみると面白いことが分かります。
本予測モデルでは株価上昇の予測だけではなく下降の予測も同時にしていますが
時々出力となる上昇/下降確信度がめちゃくちゃになる場合が存在します。
ちょうど ↓ のような出力をするときです。
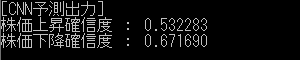
本モデルでは上昇/下降予測の出力がほぼ 0 か 1 を取るのですが
このような例外がちょこちょこあります。
そこで下記基準でデータ分けを実施してみました。
- | 上昇確信度 ー 下降確信度 | > 一定値 で 自銘柄データ使用 ・・・①
- | 上昇確信度 ー 下降確信度 | > 一定値 で 他銘柄データ使用 ・・・②
- | 上昇確信度 ー 下降確信度 | <= 一定値 で 自銘柄データ使用 ・・・③
- | 上昇確信度 ー 下降確信度 | <= 一定値 で 他銘柄データ使用 ・・・④
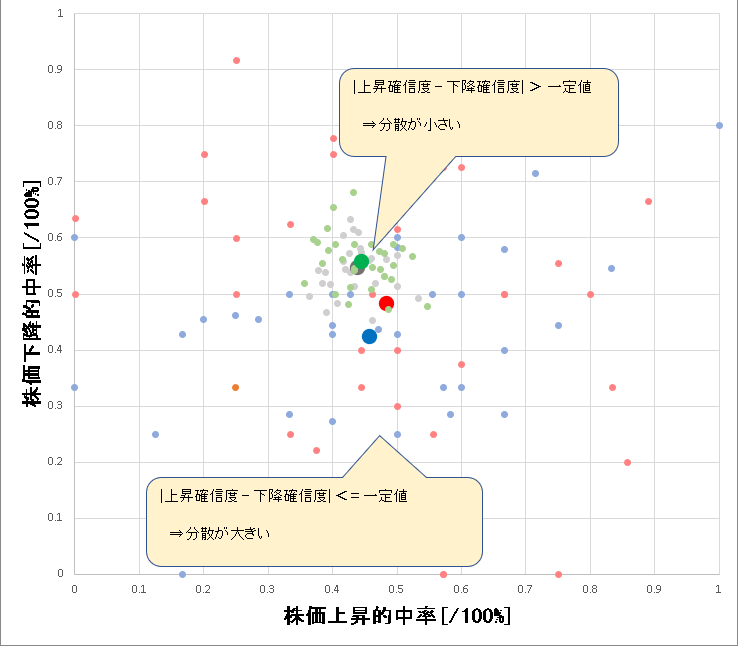
すると下記のようなプロットになりました。(それぞれの色に対応しています)
これを見ると上昇確信度と下降確信度の差が大きいほど分散が小さくなり
確信度の差が小さいほど分散が大きくなっていることが分かります。
何かヒントの予感!
分離したデータは偶然か?
先ほどのプロットを見てみると綺麗に分散の大小で別れている気がしますが偶然でしょうか?
それを調べるために『F検定』を利用します。
『F検定』とは簡単に言うとあるデータグループ間の分散が等しいかを調べる手法です。
分散が等しいかどうかは重要でt検定を実施する前段で利用されることが多いです。
明らかに見た目で分散が違うことは分かりますが①と③のデータでExcelのデータ分析機能を使って
検定を実施してみました。結果は下記のようになりました。
【株価上昇率に対する分散のF検定結果】
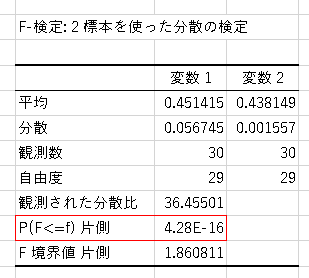
【株価下降率に対する分散のF検定結果】
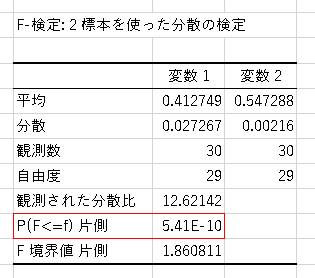
見るべきは赤枠のP値と呼ばれている値です。
このF検定の帰無仮説は「この2グループ間の分散は同じである」ということに対し
P <= 0.025 (片側) の場合、統計的5[%]水準において上記帰無仮説を棄却することができます。
今回はどちらのF検定結果も P <= 0.025 となりました。
要するにこの2グループ間の分散は異なるという事が証明できたという事です!
こういうときに統計って便利です!
しかし、なぜこんなことに???
なぜ分散が異なるデータとなったのか?
この疑問に関してですが、現状原因は分かっていません。
上昇確信度と下降確信度の差が小さいことから下記3点のように原因を予想しています。
1.上昇の場合と下降の場合でデータパターンが重複している
2.単に学習しきれていない
3.学習に必要なデータが不足している
今後の方策
先ほどの分散が大きな予測値が出る問題に対して予想する原因を3点記載しました。
ぶっちゃけ1はどうしようもありませんし、3を対応しようにも勉強不足な部分が多々あり
株式データの関係が分かっていないのです・・・。
よって消極的ですが2に対して対応を取ることとしました。
つまりモデルの改良や活性化関数の変更などを実施していき、再びモデルの出力をプロットして
改善されているか前後で比較してみたいと思います!
現在モデル改良をがんばってます!
・・・が学習結果が安定しない。
まとめ
この記事では
- 株価予測モデルの出力データ検証
- 今後の方策
についてまとめてみました!
【2021.10.06 追記】 続きの記事を書きました!

コメント